I was recently asked, “Are you a Data Scientist?” My answer: “Yes! I am an Informatician, which seems to be the same thing”. A confused reply followed: “an inform-a-what?”
This got me searching the web and checking job role definitions. The overlap between the two is huge and the overall goal of both is identical – turning data into knowledge.
So what should I be calling myself? Apparently Data Scientist is the “sexiest job of the 21st century”. Does this mean I should put my Informatics coat at the back of the wardrobe and wear the trendier Data Scientist designer label? In order to answer this question let’s do the “Data Science/Informatics” thing and take a peek at some data (frequency of internet searches, source: Google Trends).
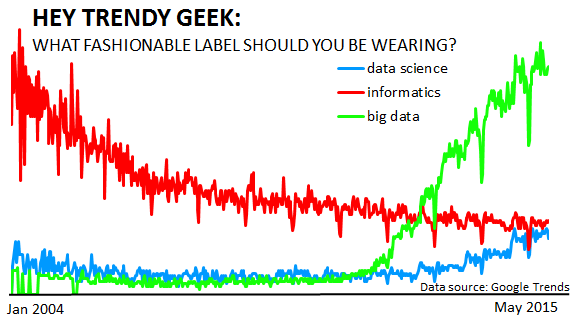
Representing term trendiness with the frequency of Google internet searches suggests that:
- Currently “Data Science” and “Informatics” are equally cool
- “Data Science” trendiness has been on a slight increase for the last couple of years. If this continues then “Informatics” is at risk of being out-trended by this time next year.
- “Big Data” took off around late 2011 with a rapid rise over the last 3 years, making it the current chart topper. As data volume increases will the term “Big Data” be too small and replaced.
- Could the increase in “Data Science” popularity be due to the “Big Data” era? At a glance the recent rise of the “Data Scientist” has occurred inside of the “Big Data” mountain, but this does not confirm any causal effects.
- A decade ago “Informatics” was as sexy as “Big Data” is now.
There is an even newer phrase on the block, the Data Artist, an expert in visualising data. One thing is very clear. Whatever labels we choose to use, we all have a common goal.
Since I am a chemist who extracts knowledge from data, I am going to stick to calling myself a Data Scientist… the “sexiest job of the 21st century”. Off to have a quick coffee before cracking on with an informatics, data artistry and data mining analysis for my next client. Now should I have a Mocha, Latte, Cappuccino with or without sprinkles hmmm?…